A common assumption is that computers can’t have emotions. But there is a strong philosophical argument that AI systems have had emotions for many decades now.
Before making an argument, we need to define “emotion”. That definition shouldn’t require consciousness self-awareness (reddit was fast to correct this) or physical manifestation.
Self-awareness can’t be a requirement for the presence of emotions because that would contradict current research findings that even simple animals have emotions. Experiments on honeybees in 2011 show that agitated honeybees display an increased expectation of bad outcomes, similar to the emotional state displayed by vertebrates. Research published in Science in 2014 concluded that crayfish show anxiety-like behavior controlled by serotonin. However, we wouldn’t consider honeybees or crayfish to be self-aware. But you don’t have to look to the animal world. When you are sleeping, you are not self-aware, yet when a bad nightmare wakes you up, would you say you didn’t experience emotions?
Physical manifestation in any form (facial expression, gesture, voice, sweating, heart rate, etc.), can’t be a requirement for the presence of emotions because it would imply that people with complete paralysis (e.g. Stephen Hawking) don’t experience emotions. And, as before, we have the sleep problem: you experience emotions in your dreams, even when your body doesn’t show it.
This is a bit of a problem. As self-awareness is not a requirement, we can’t simply ask the subject if they experience emotions. As a physical manifestation is not a requirement, we can’t simply observe the subject. So, how do we determine if one is capable of emotional response?
As a starting point, let’s look at evolution:
The evolutionary purpose of emotions in animals and humans is to direct behavior toward specific, simple, innate needs: food, sex, shelter, teamwork, raising offspring, etc.
Emotional subsystems in living creatures do that by constantly analyzing their current model of the world. Generally wanted behavior produces positive emotions (happiness, love, etc.) while generally unwanted behavior produces negative emotions (fear, sadness, etc.).
Emotions are simple and sometimes irrational, so evolution enabled intelligence to partially suppress emotions. When we sense that lovely smell of freshly baked goods, we feel a craving to eat them, but we can suppress the urge because we know they are not healthy for us.
Based on that, we can provide a more general definition of “emotion” for any intelligent agent:
Emotion is an output of an irrational, built-in, fast subsystem that constantly evaluates the agent’s world model and directs the agent’s focus toward desired behavior.
Take a look at a classic diagram of a model-based, utility-based agent (from Artificial Intelligence: A Modern Approach textbook), and you will find something similar:

Do you notice it? In the middle of the diagram stands this funny little artifact:
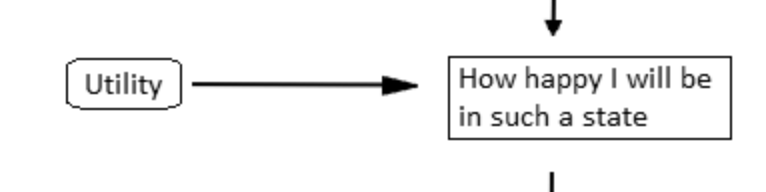
Even professional philosophers in the realm of AI have overlooked this. Many presume AI systems are rational problem solvers that calculate an optimal plan for achieving a goal. Utility-based agents are nothing like that. Utility function is always simple, ignores a lot of model details, and is often wrong. It is an irrational component of the system.
But why would anybody put such a silly thing in code? Because introducing “happiness” to an AI system solves the computational explosion problem. The real world, and even many mathematical problems, has many more possible outcomes than particles in the universe. A nonoptimal solution is better than no solution at all. And paradoxically, utility-based agents make more efficient use of computational resources, so they produce better solutions.
To understand this, let’s examine two famous AI systems from the 1990s that used utility functions to play a simple game.
The first one is Deep Blue, a computer specifically designed to crunch chess data. It was a big black box with 30 processors and 480 special-purpose chess chips, and it was capable of evaluating 200 million chess positions per second. But even that is not enough to play perfect chess, as the shannon number states that the lower bound of possible situations in a chess game is 10120. To overcome this, engineers could have limited search to only N future chess moves. But there was a better approach: Deep Blue could plan longer into the future if it could discard unpromising combinations.
Human chess players had known for a long time an incorrect but fast way to do that. Count the number of chess pieces on the board and multiply by the value of each piece. Most chess books say that your pawn is worth one point and the queen is worth nine points. Deep Blue had such a utility function, which enabled it to go many moves deeper. With the help of this utility function, Deep Blue defeated Garry Kasparov in 1997.
It is important to note two things:
- A utility function is irrational. Kids play chess by counting numbers of pieces; grandmasters do not. In the chess game of the century, 13-year-old Bobby Fischer defeated a top chess master by sacrificing the queen. He was executing a strategy, not counting pieces.
- A utility function needs to be irrational. If it were rational, it would calculate every possible move, which would make it slow and therefore defeat its purpose. Instead, it needs to be simple and very fast, so it can be calculating in every nanosecond.
This chess experiment proved that utility-based agents that use “intuition” to achieve solutions vastly outperform perfectly rational AI systems.
But it gets even better.
At the same time that IBM was pouring money in Deep Blue, two programmers started developing a downloadable chess program you could run on any PC. Deep Fritz ran on retail hardware, so it was able to analyze only 8 million positions per second—so it was 25 times slower than Deep Blue. But the developers realized they could beat the game with a better utility function. After all, that is how humans play: they are slower but have stronger intuition.
In 1995 the Deep Blue prototype lost to Deep Fritz, which was running on a 90MhZ Pentium. How is it possible that the 25-times-slower computer won? It had better utility function that made the program “happy” with better moves. Or should we say it had better “emotional intelligence”?
This shows the power of emotion. The immediacy of the real world requires that you sometimes stop thinking and just go with your gut feeling, programmed into you by billions of years of evolution. Not only is there a conflict between emotions and rationality, but different emotions also play tug-of-war with each other. For example, a hungry animal will overcome its fear and take risks to get food.
Note that in both higher-order animals and advanced AI systems, the fixed part of a utility function is augmented with utility calculation based on experience. For example, a fixed part of human taste perception is a love of sugars and a strong dislike for rotten eggs. But if one gets sick after eating a bowl of gummy bears, the association “gummy bears cause sickness” is stored and retrieved in the future, as a disgusting taste. The author of this article is painfully aware of that association, after a particular gummy bear incident from his childhood.
To summarize the main points:
- Emotions are fast subsystems that evaluate the agent’s current model of the world and constantly provide positive or negative feedback, directing action.
- Because emotional subsystems need to provide immediate feedback, they need to be computationally fast. As a consequence, they are irrational.
- Emotions are still rational on a statistical level, as they condense “knowledge” that has worked many times in the past.
- In the case of animals, utility functions are crafted by evolution. In the case of AI agents, they are crafted by us. In both cases, a utility function can rapidly look up past experience to guide actions.
- Real-world agents don’t have only one emotion but a myriad of them, the interplay of which directs agents into satisfying solutions.
In conclusion, an AI agent is emotional if it has a utility function that (a) is separate from the main computational part that contains the world model and (b) constantly monitors its world model and provides positive or negative feedback.
Utility-based agents that play chess satisfy those criteria, so I consider them emotional—although in a very primitive way.
Obviously, this is not the same as human emotions, which are much more intricate. But the principle is the same. The fact that honeybees and crayfish have very simple emotional subsystems doesn’t change the fact that they experience emotions. And if we consider honeybees and crayfish emotional, then we should do the same with complex utility-based agents.
This may feel implausible. But we need to ask ourselves, is that because the above arguments are wrong? Or, maybe, because the utility function in our brain is a little out of date?
Zeljko Svedic is a Berlin-based tech philosopher. If you liked this piece of modern philosophy, you will probably like Singularity and the Anthropocentric Bias and Car Sharing and the Death of Parking.


 Car2go decided to pimp up its rides, so now you can book a Merc:
Car2go decided to pimp up its rides, so now you can book a Merc: Citroen also decided to join the party. The company offers a fleet of mostly electric C-Zeros with
Citroen also decided to join the party. The company offers a fleet of mostly electric C-Zeros with  Volkswagen got angry that Mercedes and BMW were eating all the cake, so it purchased a
Volkswagen got angry that Mercedes and BMW were eating all the cake, so it purchased a  While Sixt is partnering with BMW, Hertz has its own
While Sixt is partnering with BMW, Hertz has its own  Don’t laugh at the idea of shared scooters. This is a cultural thing—while in the US, the ideal transportation vehicle is a sedan and in Europe a compact car, two billion people in Asia consider scooters a family transport solution. Look at this nice family in Vietnam:
Don’t laugh at the idea of shared scooters. This is a cultural thing—while in the US, the ideal transportation vehicle is a sedan and in Europe a compact car, two billion people in Asia consider scooters a family transport solution. Look at this nice family in Vietnam: And eMio is not the only one. Just
And eMio is not the only one. Just  Both Coup and eMio have an unusual charging solution: their teams go around the city and swap empty batteries for full ones.
Both Coup and eMio have an unusual charging solution: their teams go around the city and swap empty batteries for full ones.