|
Seminar Project
My seminar project was Dynamic
Rebuilding of Syntax Tree and Appliance in Construction of Combined
Language Processor. This project received the principal's award at
the University of Zagreb. The purpose of the project was to construct
algorithms and data structures for efficient incremental syntax
analysis.
Figure 2-1 shows the main windows of the demonstration program
which rebuilds the syntax tree for the code written in simple expression
language.
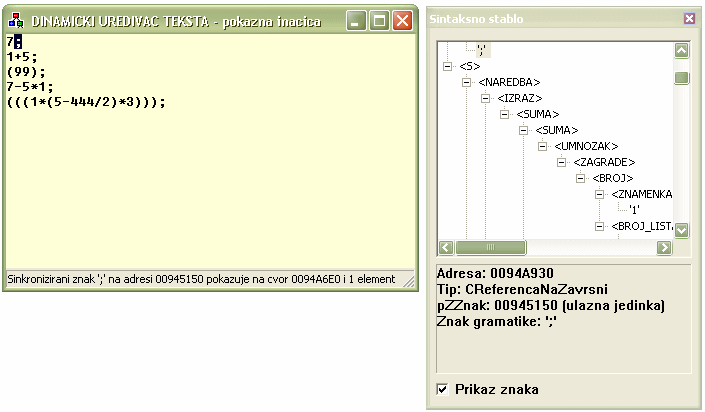
Figure 2-1: Dynamic
Rebuilding of The Syntax Tree
The main idea behind incremental algorithm is to
repair existing syntax tree by replacing just the small part which is
invalid due to recent changes in source code (keystrokes, editing
operations). Existing linear algorithms for parsing (in this case
LR(1) parsing algorithm) are not acceptable simply because they
analyze the whole source file, which is unacceptably slow for an environment
which needs to be interactive.
Unfortunately, most computer languages were never created with
incremental properties in mind. Because of that most of them have
language constructs which are hard to incrementally analyze.
For instance,
multi-line comments (like /* */ in C language) present a problem
because of their non-local nature. When the user opens a multi-line
comment (types "/*") the rest of the input file represents
an invalid
syntax (as there is no comment closing). When the user closes
a
multi-line comment (types "*/") the rest of the input file
again becomes a valid syntax structure. The
result is that the unoptimized incremental syntax analyzer parses the whole
input file every time the user types multi-line comments. C and C++ are particularly difficult to implement in
an incremental environment.
This is due to the quite awkward lexical and syntax language constructs.
For instance, C and C++ standards define a concept of the language preprocessor. Macro defined
with a language preprocessor defines text replacements in all source
files which use that macro. If the user changes a macro definition, that
modification implies lexical and syntax change in many other files,
which often requires reparsing of the entire set of input files. Except
with the preprocessor, C and C++ have issue with ambiguous syntax rules. For
instance, the following line in C++:
can represent two syntax structures:
- declaration of variable
a with type
myfile
(if myfile
is a user defined structure), or
- function call with variable
a
as function argument (if
myfile is a
user function).
In order to determine the exact context,
the parser needs
semantic information -- which makes incremental analysis much more
complex. Efficient methods for incremental analysis of different
programming languages are still a subject of discussion in scientific
literature.Some other languages are much more suitable for
incremental analysis. For instance, BASIC was created with
incrementality in mind (line-based interpreter) and represents a
good language choice for language-oriented environments. Incremental
engine developed inside this project was used in latter
graduation thesis, which has the most
recent version of incremental syntax analyzer and gives a
demonstration of the concrete usage of this engine. |